


AMD recently published a patent for spreading the load from rendering across several GPU chiplets. A game scene is divided into individual blocks and distributed to the chiplets to optimize the utilization of the shaders in games. Two-level chiplet binning is used for this.
AMD publishes patent for GPU chiplets application to create better utilization of shader technology
The new patent published by AMD opens more insights into what the company plans to do with next-level GPU and CPU technology in the coming years. At the end of June, fifty-four patent applications were revealed to be sent for publishing. It is unknown which of the over fifty patents published will be utilized in AMD’s plans. The applications discussed in the patents detail the company’s approaches over the following years.
One application that was noticed by community member @ETI1120 on the website ComputerBase, patent number US20220207827, discusses critical image data in two stages to efficiently pass the loads from rendering from a GPU over many chiplets. CPU initially applied this to the US Patent Office at the end of last year.
When image data on a GPU is rasterized by standard means, the shader unit, also known as the ALU, performs the identical task and assigns a color name to individual pixels. In turn, the textured polygons found at the specific pixel in a particular game scene are mapped directly onto the pixel. Finally, the formulated task will maintain atypical principles and only differ through other textures located at different pixels. This method is called SIMD, or Single Instruction – Multiple Data.
For most current games, shading is not the only task begotten by a GPU. But instead, several post-processing elements are included after the initial shading. Actions that the GPU would add, for example, would be anti-aliasing, shadowing, and occlusions of the game environment. However, ray-tracing happens in tandem with shading, creating a new calculation method.
When talking about the GPU controlling the graphics in current games, the load created by the computer is exponentially increased into thousands of computing units.
In games on GPUs, this computing load scales up to several thousand computing units in a somewhat ideal manner. This differs from processors in that applications have to be specifically written to add more cores. The CPU scheduler creates this action, splitting the work from the GPU into more digestible tasks processed by the compute units, also called binning. The image from the game is rendered and then divided into separate blocks that contain a set amount of pixels. The block is computed by a sub-unit of the graphics processor, where it is then synched and created. After that action, pixels waiting to be calculated are included in a block until the sub-unit of the graphics card is ultimately used. Considerations are made for the computing power of the shaders, the memory bandwidth, and the cache sizes.

AMD explains in the patent that the dividing and joining demand a thorough and complete data connection between all the elements of the GPU, which poses an issue. Links of data not located on the die have an elevated level of latency, causing the process to be slower.
CPUs have made this transition to chiplets effortlessly due to the ability to send the task over several cores, making it accessible for chiplets. GPUs do not offer the same flexibility, placing their scheduler comparable to an introductory dual-core processor.

AMD recognizes the need and attempts to make answers to these problems by altering the pipeline of rasterization and sending the tasks among several GPU chiplets, similar to CPUs. This requires advanced binning technology, which the company is introducing “two-level binning,” also known as “hybrid binning.”
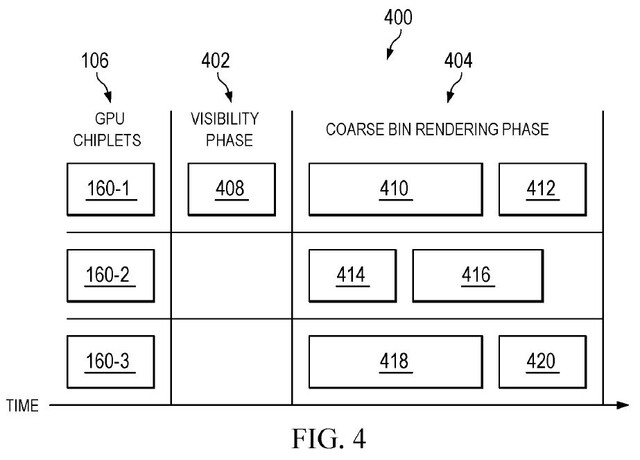
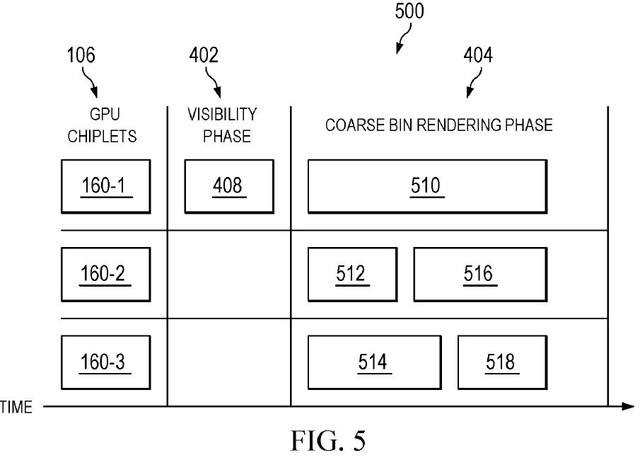
In hyper binning, the split is processed into two separate stages instead of directly processing into pixel-by-pixel blocks. The first step is to calculate the equation, taking a 3D environment and creating a two-dimensional image from the original. The stage is called vertex shading and is completed before rasterization, and the process is highly minimal on the first chiplet of the GPU. Once complete, the game scene begins to be binned, developing into coarse bins and processing into a single GPU chiplet. Then, routine tasks such as rasterization and post-processing can begin.


It is unknown when AMD intends to begin utilizing this new process or if it will be approved. However, it gives us a glimpse into the future of more efficient GPU processing.
News Sources: ComputerBase, Free Patents Online
